刚刚!梁文锋参与发表回顾性论文:DeepSeek首次揭秘V3模型背后扩展方案

DeepSeek刚刚发表了一篇名为《深入解读 DeepSeek-V3:AI 架构的扩展挑战与硬件思考》(Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures)的回顾性论文,梁文锋也是作者之一。这篇论文深入剖析了最新的大模型DeepSeek-V3及其AI基础设施扩展方案,DeepSeek-V3的实践充分证明了硬件-软件协同设计在提升AI系统可扩展性、效率和鲁棒性方面的巨大潜力

强烈推荐精读!
快速解读一下这篇论文
论文开宗明义:软硬协同
文章一上来就点明了当前大模型(LLM)发展的核心矛盾:模型规模、训练数据和算力需求飞速增长,但现有硬件架构在内存容量、计算效率和互连带宽方面都面临严峻挑战。DeepSeek-V3的成功,恰恰证明了“硬件感知模型协同设计”是解决这些挑战、实现大规模经济高效训练和推理的关键。
这篇论文的目标不是重复DeepSeek-V3的技术报告,而是从硬件架构和模型设计的双重角度,探讨它们之间复杂的相互作用,并为未来AI系统的可扩展性、成本效益提供实用蓝图
DeepSeek-V3核心设计揭秘:三大挑战,逐个击破
DeepSeek团队围绕LLM扩展的三大核心挑战——内存效率、成本效益、推理速度——对DeepSeek-V3进行了精心设计
一、内存效率:榨干每一滴显存
首先是低精度模型 (FP8)。相比BF16,FP8直接将模型权重内存占用减半,极大缓解了“内存墙”问题。这一点在后面会详细展开
其次,DeepSeek-V2/V3采用的MLA (Multi-head Latent Attention) 技术,通过一个可共同训练的投影矩阵,将所有注意力头的KV表示压缩到一个更小的“潜向量”(latent vector)中。推理时只需缓存这个潜向量,大幅降低内存消耗。论文给出的对比数据显示,DeepSeek-V3 (MLA) 每token的KV Cache仅为70.272KB,而采用GQA的Qwen-2.5 72B为327.680KB,LLaMA-3.1 405B更是高达516.096KB。MLA的优势可见一斑!
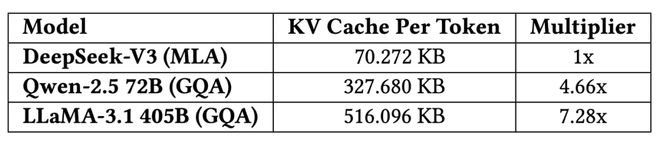
此外,论文也提及了业界其他有价值的方法,如GQA/MQA(分组/多查询注意力)共享KV对,Windowed KV(滑动窗口),以及量化压缩等。并展望了线性时间复杂度的注意力机制(如Mamba-2, Lightning Attention)和稀疏注意力的潜力
二、成本效益:MoE架构
DeepSeek-V3采用了其在V2中已被验证有效的DeepSeekMoE架构(混合专家模型)。MoE的核心优势在于“稀疏激活”:模型总参数量可以非常大,但每个token只激活一小部分专家参数
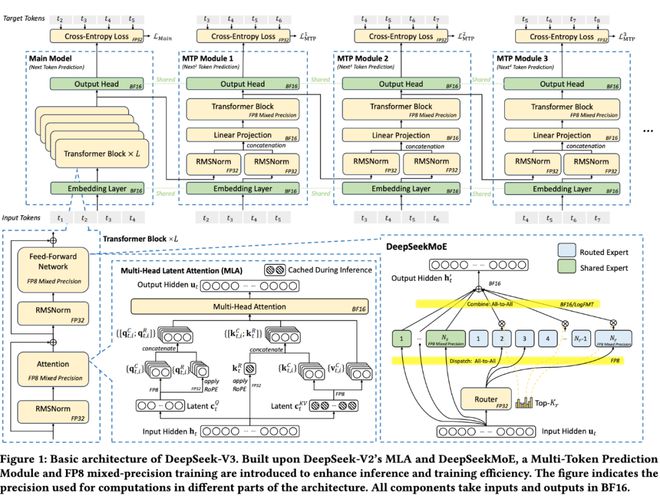
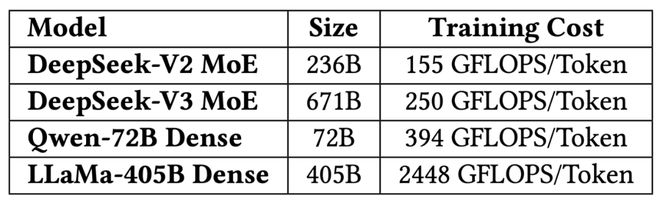
这使得训练成本显著降低。DeepSeek-V2有236B参数,每token激活21B;DeepSeek-V3扩展到671B参数,每token激活仅37B。相比之下,像Qwen2.5-72B和LLaMA3.1-405B这样的密集模型,训练时所有参数都处于激活状态。从算力消耗对比 来看,DeepSeek-V3每token训练成本约250 GFLOPS,远低于LLaMA-405B的2448 GFLOPS,甚至低于Qwen-72B的394 GFLOPS
MoE模型的低激活参数特性,也使得在个人电脑的AI SoC上也能实现不错的推理速度(如DeepSeek-V2在PC上可达近20 TPS甚至更高),为个性化LLM智能体和本地化部署铺平了道路。使用KTransformers推理引擎,DeepSeek-V3完整模型能在消费级GPU(约1万美元成本)的服务器上跑到近20 TPS
三、推理速度:分秒必争
DeepSeek模型从设计之初就考虑了通过双micro-batch重叠(dual micro-batch overlap)来隐藏通信延迟,最大化GPU利用率。生产环境中还采用prefill和decode分离的架构,针对性优化。
对于MoE模型,专家并行(EP)的All-to-All通信是瓶颈。论文以一个例子说明:若每设备一个专家,一次处理32个token,使用CX7 400Gbps InfiniBand网卡,一次EP(dispatch和combine)的通信时间约为120.96µs。在双micro-batch重叠的理想情况下,每层总时间约为241.92µs。DeepSeek-V3有61层,则总推理时间约为14.76ms,理论TPOT(Time Per Output Token)上限约为67 tokens/s。如果换成GB200 NVL72(900GB/s单向带宽),通信时间降至6.72µs,理论TPOT能飙升到1200 tokens/s!这生动展示了高带宽互连的巨大潜力。
受Gloeckle等人工作的启发,DeepSeek-V3引入了多令牌预测 (MTP, Multi-Token Prediction) 框架。传统自回归模型一次解码一个token,MTP则允许模型以较低成本生成多个候选token并并行验证,类似 speculative decoding。这能显著加速推理。实际数据显示,MTP对第二个后续token的接受率在80%-90%,使生成TPS提升1.8倍。同时,MTP也增大了推理batch size,有利于提升EP计算强度和硬件利用率。
像OpenAI的o1/o3系列、DeepSeek-R1等推理模型,以及PPO、DPO等RL流程,都极度依赖高token输出速度。
低精度驱动设计:FP8混合精度训练的探索
DeepSeek-V3的一大亮点是成功应用了FP8混合精度训练。在此之前,开源社区几乎没有基于FP8训练的大模型。
FP8的优势在于显著降低内存占用和计算量。但其在Hopper GPU上也面临硬件局限性:一是累积精度受限,Tensor Core在FP8累积时,虽然中间结果用FP22存储,但从32位尾数乘积右移对齐后,只保留最高的13位小数进行加法,这会影响大模型训练稳定性;二是细粒度量化开销大,像tile-wise(激活)和block-wise(权重)这样的细粒度量化,在将部分结果从Tensor Core传回CUDA Core进行缩放因子乘法时,会引入大量数据搬运和计算开销。
对此,DeepSeek的建议是:未来硬件应提高累积精度(如FP32)或支持可配置的累积精度;同时,Tensor Core应能原生支持细粒度量化,直接接收缩放因子并执行带组缩放的矩阵乘法,避免频繁数据搬运。NVIDIA Blackwell的microscaling数据格式正是这一方向的体现。
DeepSeek团队还尝试了一种名为LogFMT-nBit(对数浮点格式)的数据类型用于通信压缩。它将激活值从线性空间映射到对数空间,使得数据分布更均匀。但其局限性在于LogFMT数据在GPU Tensor Core计算前仍需转回FP8/BF16,log/exp运算开销和寄存器压力较大。因此,尽管实验验证了其有效性,但最终并未实际采用。他们建议未来硬件原生支持FP8或定制精度格式的压缩/解压单元
互连驱动设计:榨干H800的每一分带宽
DeepSeek-V3使用的NVIDIA H800 SXM节点,NVLink带宽有所缩减(从H100的900GB/s降至400GB/s)。为弥补这一不足,每节点配备了8个400G InfiniBand CX7 NIC
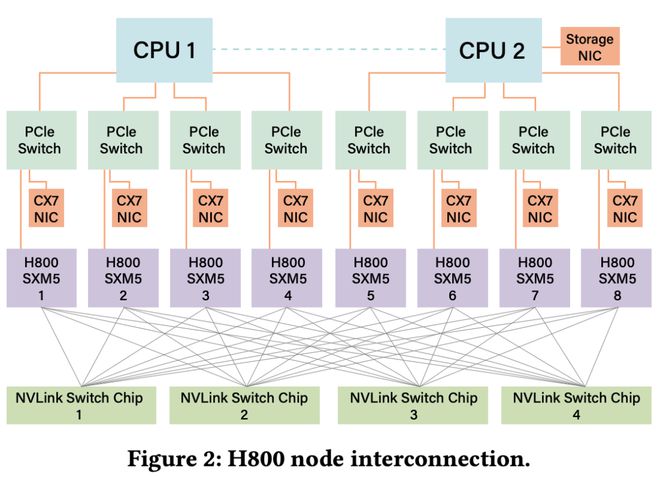
在硬件感知的并行策略上,DeepSeek训练中因NVLink带宽受限而避免使用张量并行(TP),推理时可选择性使用;采用DualPipe算法重叠Attention和MoE计算与通信来增强流水线并行(PP);并借助8个IB NIC实现超40GB/s的All-to-All通信速度以加速专家并行(EP)
模型协同设计方面,由于H800的NVLink(有效约160GB/s)和IB NIC(有效约40GB/s)带宽差异巨大,DeepSeek-V3引入了节点限制路由 (Node-Limited Routing) 的TopK专家选择策略:将256个路由专家分为8组,每组32个专家部署在单个节点上,并从算法上确保每个token最多路由到4个节点。这缓解了IB通信瓶颈。
关于Scale-Up与Scale-Out的融合,当前局限在于GPU SM既要处理网络消息,又要通过NVLink转发数据,消耗计算资源。DeepSeek建议未来硬件应集成统一网络适配器、专用通信协处理器、灵活的转发/广播/Reduce机制、硬件同步原语、动态NVLink/PCIe流量优先级、I/O Die Chiplet集成NIC,以及CPU-GPU Scale-Up域互连。
大规模网络驱动设计:多平面胖树
DeepSeek-V3训练中部署了多平面胖树 (MPFT, Multi-Plane Fat-Tree) Scale-out网络。每节点8 GPU + 8 IB NIC,每个GPU-NIC对属于一个独立网络平面。
MPFT的优势包括:作为多轨胖树 (MRFT) 的子集可利用NCCL优化;成本效益高,用两层胖树即可支持超万个端点;各平面流量隔离,单平面拥塞不影响其他;两层拓扑延迟更低且鲁棒性好。性能分析显示,其All-to-All通信和EP场景性能与单平面MRFT非常接近,在2048 GPU上训练DeepSeek-V3的指标也几乎一致。
在低延迟网络方面,IB延迟优于RoCE,但IB成本高、交换机端口密度低。对RoCE的改进建议包括:专用低延迟RoCE交换机、优化路由策略(如自适应路由)、改进流量隔离/拥塞控制机制。同时,DeepSeek也利用了InfiniBand GPUDirect Async (IBGDA) 技术来减少网络通信延迟。
对未来AI硬件架构的展望
论文最后,DeepSeek团队基于实践经验,对未来AI硬件设计提出了更宏观的思考:
1. 鲁棒性挑战:应对互连故障、单硬件故障、静默数据损坏等问题,硬件需集成高级错误检测机制并提供诊断工具
2. CPU瓶颈与互连:解决PCIe带宽瓶颈、高内存带宽需求、CPU单核性能及核心数问题,建议CPU-GPU直接互连或集成到Scale-up域
3. 迈向AI智能网络:发展硅光子、高级端到端拥塞控制、自适应路由、高效容错协议和动态资源管理
4. 内存语义通信与顺序问题:硬件应支持内建的内存语义通信顺序保证(如acquire/release语义),消除sender端fence
5. 网络内计算与压缩:优化EP的dispatch和combine,原生集成LogFMT等压缩技术
6. 内存为中心的创新:推广DRAM堆叠加速器和System-on-Wafer (SoW)技术。
参考:
星标AI寒武纪,好内容不错过
用你的赞和在看告诉我~
求赞
相关文章

莱恩精工:上市计划二度“刹车” 信披质量或现疑云
《金证研》南方资本中心 望山/作者 西洲 映蔚/风控 在申报北交所上市之前,苏州莱恩精工合金股份有限公司(以下简称“莱恩精工”)曾冲击创业板并拟募集资金5.3亿元,后因主动撤稿而终止上市进程。此番申报...

八旬老人花105万买基金亏了30万,状告银行,法院判了!案涉产品曾为博时旗下百亿爆款基金
红星资本局6月1日消息,近日,裁判文书网披露的一份终审民事判决书显示,一位年过八旬的投资者在2021年投入105万元购买一只公募基金产品,两年多时间就亏损约30万元,故诉至法院,要求相关代销银行承担赔...

人设垮了,宗馥莉辞职后还有什么前途?丨正经深度
来源丨正经社(ID:zhengjingshe) (本文约为2700字) “留洋精英”“大女主” 宗馥莉,再也难以“以退为进”了。 10 月 10 日晚间,娃哈哈官方回应正式确认,宗馥莉已于 9 月 1...

腾讯投资超2亿美元的公司,做起线下生意
二手电商市场的热闹景象,正在从线上转向线下。 当闲鱼忙着把社区小店开进各个城市的街头巷尾时,另一位二手电商玩家转转直接砸下3000平方米的超级筹码——6月9日,转转集团旗下首家二手多品类循环仓店“超级...

“一日店长”流量狂欢局,有人倒贴几千元“打工”
“这里也有一日店长?”这个五一,“一日店长”的身影随处可见——奶茶店、服装店,甚至在科技属性较强的华为体验门店里,都不乏高颜值“店长”坐镇。 “合肥华为这个帅哥店员是谁”“偶遇一日店长我又幸福了”的帖...

绿洲资本张津剑:如果你认为AI和具身的机会是星辰大海,那就没有泡沫
一面是动辄上亿融资的种子轮和天使轮,一面是部分投资机构退出具身智能项目的现状和确实还遥远的商业化。该如何看待这些同时发生在眼下的投资现象? “如果你认为这个时代的机会是一个啤酒杯,那今天是有泡沫的,但...
发表评论

 豫ICP备2024079567号-1
豫ICP备2024079567号-1